
The Challenge
I wanted to build a scheduling platform like Cal.com with three constraints:
- Budget: Under $50/month
- Performance: Sub-100ms response times globally
- Scalability: Handle 10k+ users later
Here's the architecture I chose and why it works (plus where it breaks).
System Architecture
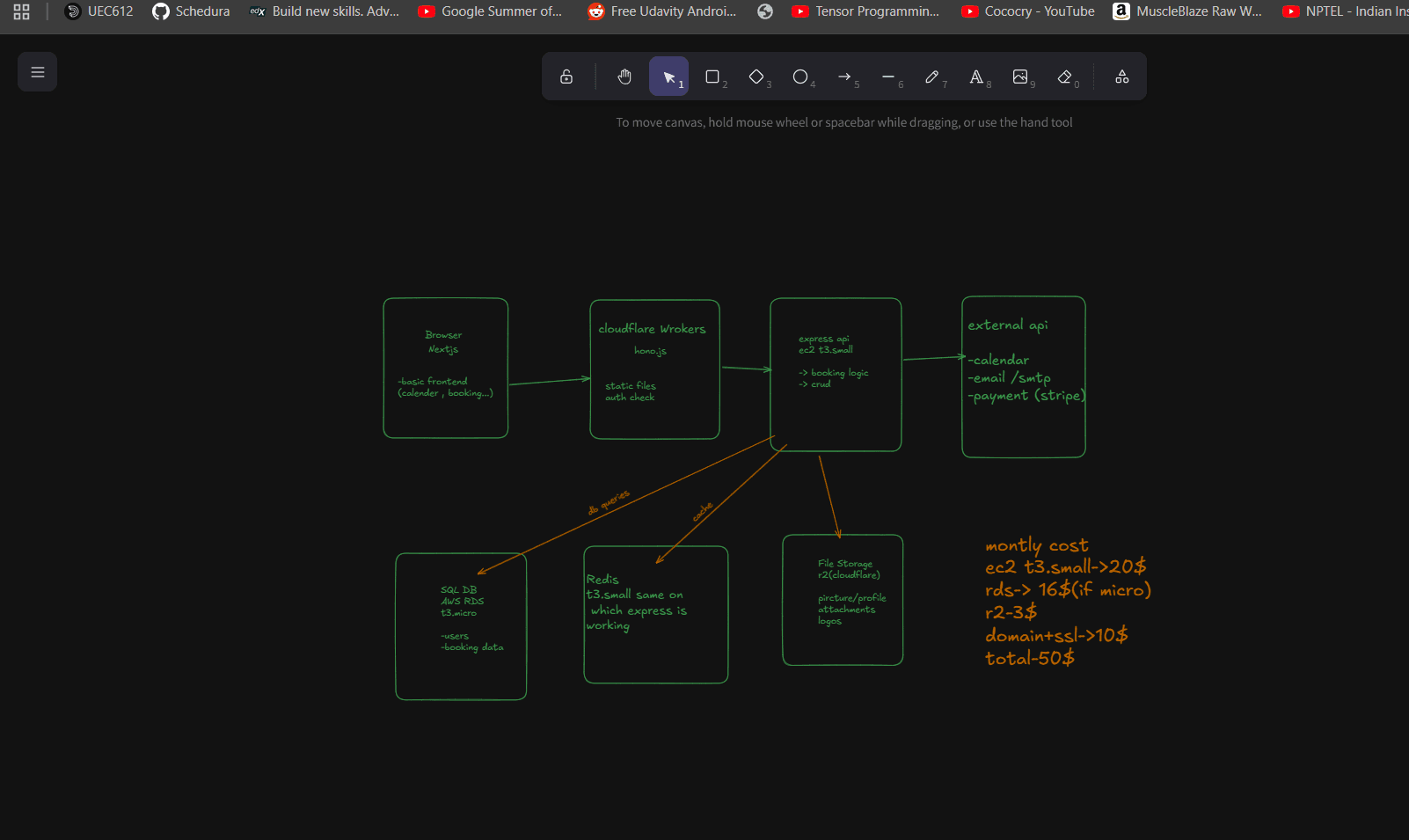
The Stack: 4 Components, Maximum Impact
1. Cloudflare Workers + Hono.js (The Bouncer)
Why: 100k free requests/day, sub-50ms global latency, built-in DDoS protection
What it does:
- Serves static files (HTML, CSS, JS)
- Basic auth validation (JWT verification)
- Rate limiting (100 req/min per IP)
- Blocks 80% of requests from hitting expensive servers
// Lightweight auth check
app.use('/api/*', async (c, next) => {
const token = c.req.header('Authorization')
if (token && !await verifyJWT(token)) {
return c.json({error: 'Invalid token'}, 401)
}
await next()
})2. Express.js on AWS EC2 (The Brain)
Why: No cold starts, predictable costs, WebSocket support
Handles: Booking logic, user management, calendar integrations, email notifications
Why not Lambda? Cold starts (2-3 seconds) kill booking experience.
3. PostgreSQL on RDS (The Memory)
Why: ACID transactions prevent double-bookings, complex availability queries
-- Find available slots (try this in MongoDB!) SELECT time_slot FROM generate_series( '09:00'::time, '17:00'::time, '30 minutes' ) WHERE NOT EXISTS ( SELECT 1 FROM bookings WHERE time_slot BETWEEN start_time AND end_time );
4. Redis + Cloudflare R2 (The Cache & Storage)
- Redis: Sessions, rate limits (runs on same EC2 = $0 extra)
- R2: Profile pics, attachments (10x cheaper than S3)
How a Booking Actually Works
- User visits
/book/john→ Workers serve static page (50ms globally) - Selects time slot → Workers check auth, forward to Express (100ms)
- Express creates booking → PostgreSQL transaction + Redis cache (200ms)
- Background job → Send emails, sync calendar (async)
Total user wait time: 300ms
Cost Breakdown: Every Dollar Justified
- EC2 t3.small: $20 (API server)
- RDS t3.micro: $16 (PostgreSQL database)
- Cloudflare R2: $3 (file storage)
- Domain: $10
- Workers, Redis, DDoS protection: FREE
Total: $49/month
Compare to alternatives:
- Vercel + PlanetScale: $80-150/month
- Firebase: $100-300/month
- AWS Lambda setup: $60-120/month
Scaling Path: No Rewrites Needed
- Phase 1 (MVP): Current setup
- Phase 2 (1k-10k users): Add read replica ($16), upgrade EC2 ($20)
- Phase 3 (10k+ users): Load balancer, multiple instances, microservices
Each phase builds on the previous—no architecture rewrites.
Where This Architecture BREAKS 💥
Let me be honest about the weaknesses:
1. Single Point of Failure
Problem: One EC2 instance goes down = entire API is down
Reality: 99.5% uptime means ~36 hours downtime/year
Mitigation: Health checks, auto-restart, but still risky for production
2. Database Becomes Bottleneck
Problem: t3.micro has ~100 connection limit
Reality: Breaks around 1000 concurrent users
Mitigation: Connection pooling helps, but you'll hit limits fast
3. No Geographic Distribution
Problem: API server in one region (say US-East)
Reality: Users in Asia get 300-500ms latency for bookings
Impact: Poor UX for global users
4. Limited Real-time Features
Problem: WebSockets don't scale across multiple instances easily
Reality: Real-time availability updates break when you scale
Impact: Users might see stale availability data
5. Vendor Lock-in Risks
Problem: Heavy dependency on Cloudflare ecosystem
Reality: If Cloudflare changes pricing/features, you're stuck
Impact: Migration complexity increases over time
6. Development Complexity
Problem: Managing edge logic vs server logic
Reality: Debugging across Workers + EC2 is harder than monolith
Impact: Slower feature development, more bugs
7. Limited Background Job Processing
Problem: Redis queue on single EC2 instance
Reality: Email sending, calendar sync can back up and fail
Impact: Users don't get confirmations, calendars out of sync
When NOT to Use This Architecture
❌ Don't use this if:
- You need 99.99% uptime SLA
- You have global users who need <100ms API responses
- You're building complex real-time collaboration features
- Your team isn't comfortable with distributed systems debugging
- You need to handle traffic spikes >10x normal load
✅ Perfect for:
- MVP with <10k users
- Budget-conscious startups
- Simple booking workflows
- Single-region users initially
- Learning system design
Key Lessons Learned
- Start simple, scale smart - This architecture buys you time to validate product-market fit
- Edge-first saves money - 80% cost savings by handling requests at the edge
- Monitoring is crucial - Single points of failure require excellent monitoring
- Plan your breaking points - Know exactly when you'll need to upgrade each component
The Bottom Line
This architecture works brilliantly for getting to market fast and cheap. It fails when you need enterprise reliability or global performance.
My recommendation: Use this to build your MVP, get your first 1000 users, and generate revenue. Then invest that revenue in a more robust architecture.
The best architecture isn't the most scalable—it's the one that gets you to profitability.